Claude Fable 5 vs Opus 4.8: Which Model Should You Actually Use?
July 3, 2026
July 3, 2026
July 3, 2026
July 3, 2026
Anthropic released Claude Fable 5 on June 9, 2026 — the first Mythos-class model available to the general public, sitting a full tier above Opus. Although it’s been offline since June 12 due to a government directive over safety concerns of a method to disable Fable’s safety features, it’s still the most expensive and advanced model in Anthropic’s lineup.
That raises an obvious question for any team already running Opus 4.8: is the upgrade worth double the price?
TL;DR — What is the difference between Fable 5 and Opus 4.8?
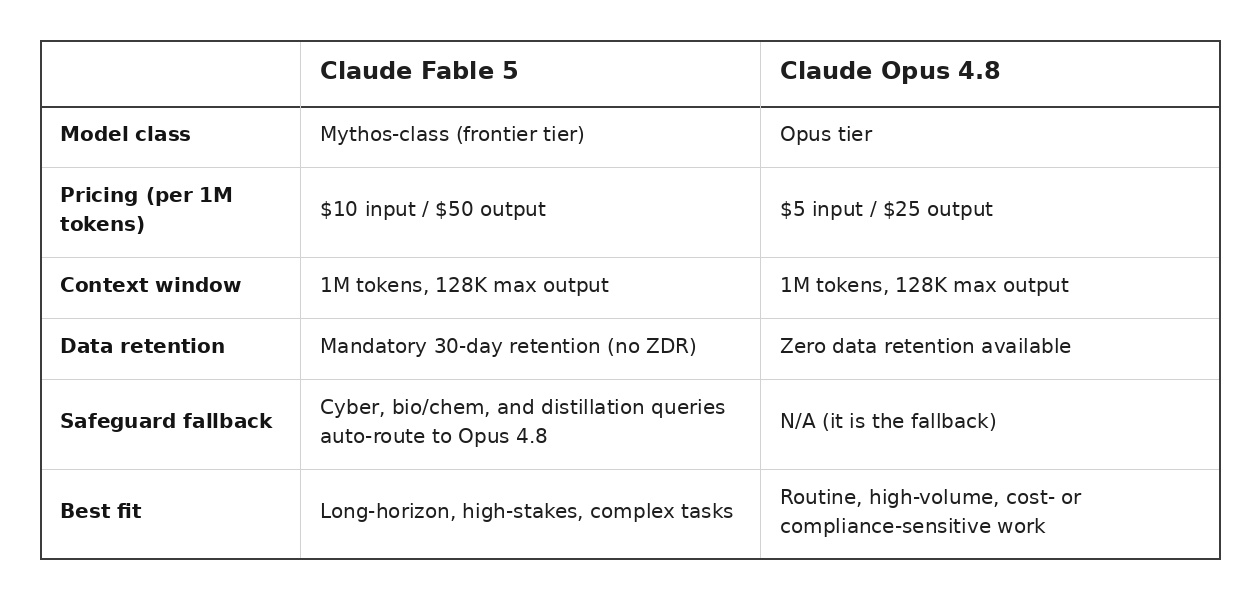
Fable 5 is a higher-capability model built for long, complex, autonomous work: large code migrations, multi-day agent runs, deep research, and dense knowledge tasks. It costs twice as much as Opus 4.8 ($10/$50 vs $5/$25 per million tokens) and carries mandatory 30-day data retention. Opus 4.8 is cheaper, supports zero data retention, and handles most routine work just as well. Reach for Fable 5 when the task is hard enough that the gap shows up — and stay on Opus 4.8 everywhere else.
Claude Fable 5 vs Opus 4.8: Quick Comparison
Pro Tip 💡: Whichever model you pick, your output is only as good as your input. Tactiq is a Chrome extension that creates a clean transcript of your meetings to feed into Claude, resulting in accurate and structured insights to work from instead of a messy recap.
Benchmark Comparison: How Fable 5 and Opus 4.8 Stack Up
Coding and agentic tasks (SWE-bench Pro, FrontierCode)
Coding is where Fable 5 pulls away hardest. On SWE-bench Pro, it scores 80.3%, against 69.2% for Opus 4.8 (and 58.6% for GPT-5.5). The gap widens on the hardest agentic work: on Cognition's FrontierCode Diamond, Fable 5 hits 29.3% — more than double Opus 4.8's 13.4%.
Notably, Fable 5 leads even at medium reasoning effort, so it doesn't always need maximum tokens to win. Real-world signals back this up: Stripe reported a codebase-wide migration in a 50-million-line Ruby project completed in a single day.
Knowledge work and reasoning (GDPval-AA)
On GDPval-AA, the professional knowledge-work rating, Fable 5 posts 1932 and tops the leaderboard, with strong showings on senior-level finance and legal reasoning. It also leads on Humanity's Last Exam with tools (64.5% vs Opus 4.8's 57.9%). For analysts, consultants, and researchers, that translates into higher-fidelity outputs on dense, multi-document problems.

Where the gap narrows
The premium doesn't buy a uniform leap. On GDPval-AA, Fable 5 leads Opus 4.8 by only about 42 Elo — a real edge, but far narrower than its coding lead. On saturated benchmarks like OSWorld, the margin shrinks further.
And in the guarded domains — cybersecurity, biology/chemistry, and model distillation — Fable 5's safety classifier reroutes the request to Opus 4.8 anyway (in fewer than 5% of sessions, with the user notified). On those queries, you are effectively running Opus 4.8 and being billed at Opus 4.8 rates.
Pricing: What You're Actually Paying for
Both Opus 4.8 and Fable 5 were originally available starting on the $20 Pro plan, but following the temporary suspension of Fable, only Opus is currently available on the Pro Plan.
Originally, Fable cost twice as much at $10/$50 per million tokens, exactly double Opus 4.8's $5/$25. Batch processing and prompt caching soften that — batch runs at $5/$25 and cached input gets a 90% discount — but the 2x premium on standard traffic is the number that matters.
That premium isn't the whole story. Fable 5's token efficiency partially offsets the gap: because it solves harder problems in fewer turns (and often at lower reasoning effort), the cost per completed job can land closer than the per-token rate suggests, and occasionally lower. On a two-month task compressed into a day, price stops being the deciding factor.
The other cost is compliance, not dollars. Fable 5 is a covered model with mandatory 30-day data retention — zero data retention is not available. Anthropic uses retained prompts and outputs to run its safety classifiers, says the data isn't used for training, and logs all human access.
For a regulated enterprise where compliance is a concern, Opus 4.8 supports ZDR, and Fable 5 does not.
When to Use Claude Fable 5 vs Opus 4.8
Use Fable 5 for:
- Long-horizon, multi-step agentic tasks — large migrations, multi-day agent runs that must hold context the whole way.
- Complex coding where quality matters more than per-token cost.
- Deep analysis, research, or high-fidelity outputs on problems where Opus has plateaued.
- Long documents with dependent sections, where losing the thread mid-way is expensive.
Stick with Opus 4.8 for:
- Well-scoped, routine tasks such as blog posts, articles, marketing copy, and summarizing documents. Fable 5's edge never shows up.
- High-volume workloads, where the 2x price compounds fast.
- Latency-sensitive use cases.
- Cybersecurity, bio, or chem domains — Fable 5 falls back to Opus 4.8 anyway.
- Zero data retention requirements — Opus 4.8 is the only option that qualifies.
How to route between both
Don't treat this as either/or. Treat the two models as a pair and route by task, using complexity and cost-sensitivity as your triggers. Here's how to set that up:
Step 1: Inventory your workloads. List your recurring task types (coding, research, doc generation, agent runs, summarization, etc.) and tag each one on two axes: how complex/failure-prone it is, and how volume- or latency-sensitive it is. This map is what your routing rules will key off.
Step 2: Make Opus 4.8 your default. Route everything to Opus 4.8 as the baseline. It's the cheaper, faster, broadly capable option, so escalate away from it only when necessary.
Step 3: Define your escalation triggers. Determine what needs to be sent to Fable 5. If a task doesn’t fall under these, it stays on Opus:
- long-horizon agent runs that must hold context end-to-end
- complex coding where quality outweighs per-token cost
- deep analysis where Opus has plateaued
- long documents with dependent sections
Step 4: Lock in the hard exclusions. Some traffic never goes to Fable 5 regardless of complexity. Set these as non-negotiable rules so they can't be accidentally rerouted.
- zero-data-retention workloads (only Opus 4.8 has zero data retention)
- anything in cyber, bio, or chem domains (Fable 5 falls back to Opus on these)
Step 5: Validate on your own prompts. Before flipping any production traffic, A/B the candidate "tail" tasks on both models using your actual prompts and outputs. Confirm Fable 5's edge actually shows up on the work you do before you pay the extra cost for it.
Step 6: Add fallback handling. Build graceful degradation so a reroute or model issue doesn't surprise you: retry/fallback logic, clear logging of which model served each request, and set alerts if a task class starts landing on the wrong model.
Step 7: Monitor cost and quality together. Track spend against quality and success rate on the tail tasks. Re-tune your triggers as either model improves or your workload mix shifts.
The short version: default to Opus 4.8, escalate only the long, hard, autonomous jobs to Fable 5, keep compliance- and latency-bound traffic locked to Opus, and validate before you flip.
How to Get More Out of Either Model with Tactiq
Model choice is only half the equation — the other half is what you feed it. Tactiq captures clean, structured meeting transcripts you can hand directly to Claude for summaries, action items, decision logs, and follow-up analysis. There's no manual copy-paste: export straight from Tactiq into your Claude workflow, so the model works from an accurate record instead of your best recollection.
Here's what that looks like in practice. Say you run a weekly product sync. In Tactiq, you let the meeting record and transcribe live, then use the AI Actions to auto-tag decisions and owners as the call happens.
Afterwards, you export the structured transcript — speaker labels, timestamps, and all — and hand it to Claude with a single instruction: "Pull every decision and its owner into a decision log, list open action items by assignee, and flag anything left unresolved." Claude then works from the verbatim record, not a half-remembered summary, so nothing quietly disappears between the call and the follow-up.
And because Tactiq has an MCP, it can connect directly to Claude, letting either model pull the meeting context as part of an automated pipeline rather than a one-off prompt.
Conclusion
The decision comes down to one line: Fable 5 for long, complex, high-stakes tasks; Opus 4.8 for cost-sensitive, routine, or sensitive-domain work. Fable 5 doesn't replace Opus — it stacks on top of it for the problems Opus can't quite hold together.
But the model you choose matters less than the quality of the input you give it. A precise, well-structured prompt on Opus 4.8 will beat a vague one on Fable 5 every time. Start there.
Connect Tactiq to your Claude workflow and turn every meeting into a clean, ready-to-use context for whichever model you point at it.
Fable 5 is a premium Mythos-class model for complex, autonomous tasks. It beats Opus 4.8 on difficult coding and reasoning benchmarks but costs twice as much and requires 30-day data retention. Opus 4.8 is cheaper, supports zero data retention, and is sufficient for most everyday work.
For complex, long-term tasks like large migrations, multi-day agent runs, or deep research, the higher cost can be worth it due to better efficiency and success rates. For routine or high-volume work, however, the 2× premium usually isn’t justified.
Use Fable 5 when the task is complex, multi-step, and quality-critical, and when 30-day data retention is acceptable. Default to Opus 4.8 for routine, latency-sensitive, high-volume, or zero-retention workloads.
No. It reroutes only when a query trips its cybersecurity, biology/chemistry, or distillation classifiers — fewer than 5% of sessions on average. You're notified when it happens, and those requests are billed at Opus 4.8 rates.
Capture the meeting in Tactiq, then export the transcript directly into Claude for summaries, action items, or analysis. Because Tactiq supports MCP, it can connect to Claude so either model pulls your meeting context automatically — no manual copy-paste.
Related articles







Want the convenience of AI summaries?
Try Tactiq for your upcoming meeting.
Want the convenience of AI summaries?
Try Tactiq for your upcoming meeting.
Want the convenience of AI summaries?
Try Tactiq for your upcoming meeting.