¿Cuál es el límite de tokens para ChatGPT 3.5 y ChatGPT 4?
December 19, 2023
December 19, 2023
January 10, 2026
January 10, 2026

Chat GPT puede manejar grandes cantidades de texto. Sin embargo, cada chat, mensaje y respuesta sigue teniendo un límite simbólico.
Estos límites afectan a la cantidad de contexto que puede procesar un modelo, a la duración de una respuesta y a la forma en que ChatGPT recuerda los mensajes anteriores. Las reglas también han cambiado mucho desde la GPT-3.5 y las primeras GPT-4.
En esta guía, aprenderás lo siguiente:
- Qué es un token de ChatGPT y cómo se mide el uso del token
- En qué se diferencian los límites de los tokens entre los modelos y plataformas de ChatGPT
- Los límites actuales de los tokens para GPT-3.5, GPT-4, GPT-4o y GPT-4.1
- Formas prácticas de trabajar dentro de los límites del modelo
- Cuando herramientas como Tactiq mejoran los flujos de trabajo de formato largo más allá del tamaño de un token
¿Qué es un token de ChatGPT?
Un token de ChatGPT es una unidad de texto que procesa un modelo de lenguaje.
Un token puede ser:
- Una sola palabra
- Parte de una palabra
- Signos de puntuación o símbolos
- Espacios o caracteres no ingleses
De media, una ficha equivale a unas 0,75 palabras en inglés. Esta medición es uniforme en todos los modelos.
El recuento de palabras y el recuento de fichas están relacionados, pero no son lo mismo. Las palabras más largas, el código y los textos que no están en inglés suelen utilizar más símbolos de los esperados.
Los tokens se utilizan durante toda la interacción:
- Mensaje del sistema
- Mensaje del sistema
- Entrada del usuario
- Respuesta de la modelo
Cuando se alcanza el límite de fichas del modelo, el modelo debe acortar o detener su salida.
Puedes acceder Tokenizador de OpenAI para visualizar cómo su modelo de lenguaje de IA tokeniza un texto y muestra su recuento total de tokens. Este es un ejemplo de texto que ingresé en Tokenizer:
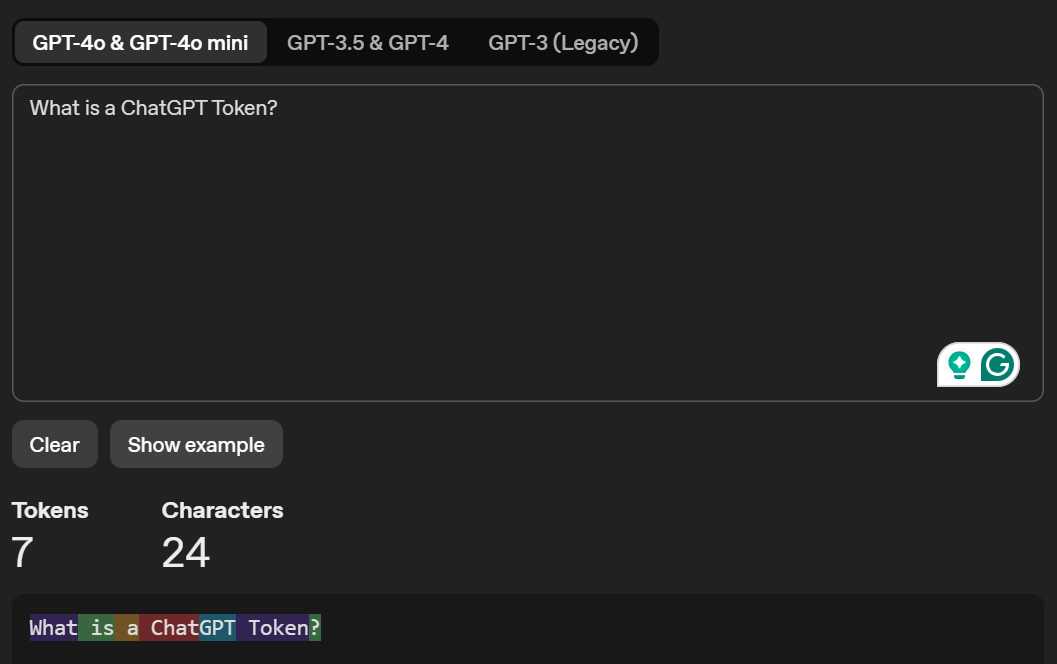
También puede obtener más información sobre límites de tokens de ChatGPT gratuitos frente a los de pago.
Consejo profesional: Las transcripciones de las reuniones suelen superar los 20 000 tokens, lo que te obliga a fragmentar el texto o perder el contexto en ChatGPT. Tactiq captura y resume automáticamente las reuniones de Zoom, Google Meet y Microsoft Teams. No es necesario poner límites de tokens ni copiar y pegar.
¿Cuál es el límite de fichas de ChatGPT-3.5?
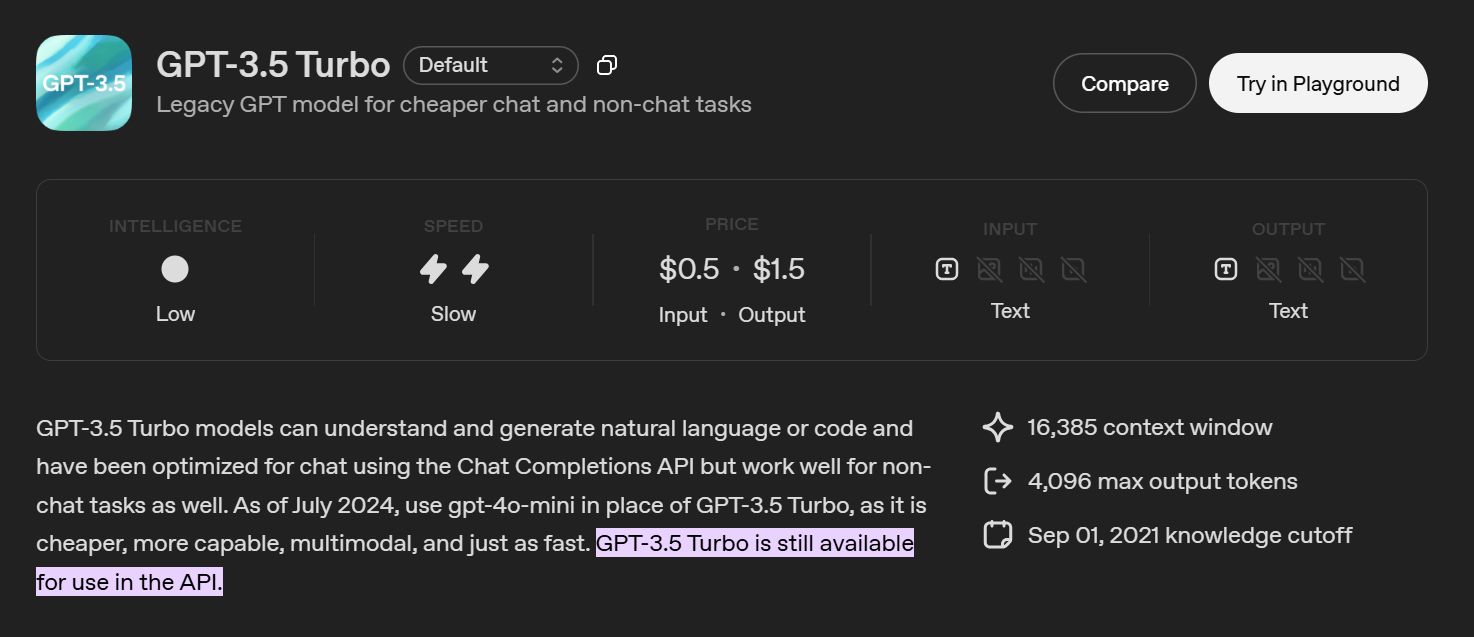
GPT-3.5 ahora se considera un modelo heredado de ChatGPT. La mayoría de los usuarios ya no lo ven en la interfaz de ChatGPT. Está disponible principalmente a través de la API de ChatGPT.
El modelo gpt-3.5 turbo estándar admite:
- 16.385 tokens en total por solicitud de API
- Los tokens se comparten entre la entrada, los mensajes del sistema, el historial de conversaciones y la salida
- La respuesta del modelo debe ajustarse al presupuesto simbólico restante
Un mensaje largo o una entrada grande reducen el tamaño máximo de respuesta.
Donde todavía se usa GPT-3.5
- Herramientas y scripts basados en API
- Tareas sensibles a los costos
- Mensajes breves y flujos de chat sencillos
El GPT-3.5 no está diseñado para transcripciones largas, documentos grandes o razonamientos complejos. Los modelos más nuevos manejan una mayor longitud de contexto y una salida estructurada de manera más confiable.
¿Cuál es el límite de fichas de ChatGPT-4?
ChatGPT-4 no tiene un límite de token fijo. Los límites varían según modelo y plataforma.
GPT-4 heredado
En su mayoría obsoleto.
- Longitud del contexto: ~8.192 fichas
Chat GPT-4O (Chat GPT)
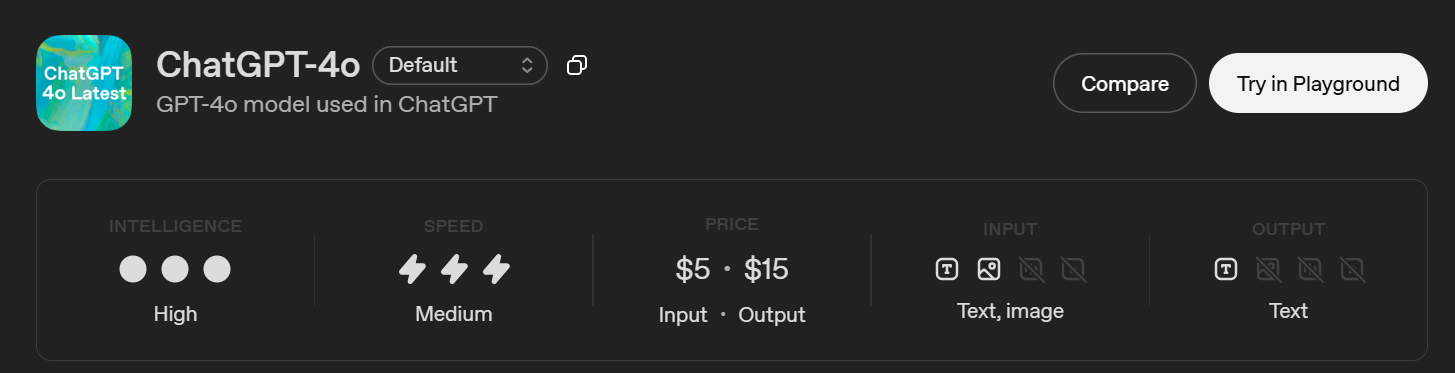
Este es el modelo GPT-4 usado en ChatGPT.
- Ventana de contexto: 128 000 fichas
- Salida máxima: 16.384 fichas
- Punto límite de conocimiento: 1 de octubre de 2023
ChatGPT sigue aplicando límites de respuesta, por lo que el modelo puede aceptar entradas grandes pero devolver una respuesta más corta.
GPT-4.1 (solo API)
Diseñado para cargas de trabajo estructuradas y de formato largo.
- Ventana de contexto: 1.047.576 fichas
- Salida máxima: 32.768 fichas
- Punto límite de conocimiento: 1 de junio de 2024
Punto clave
No hay un límite único de tokens de ChatGPT-4. Los límites dependen de:
- El modelo ChatGPT
- Interfaz de usuario de ChatGPT frente a API de OpenAI
- Longitud del contexto frente al límite de salida
¿Cómo funcionan los límites de los tokens de ChatGPT?
Si has usado Chat GPT para sesiones más largas, probablemente hayas notado que las respuestas se acortan con el tiempo. Hemos visto que esto sucede después de pegar un texto largo, continuar una conversación o hacer preguntas de seguimiento sobre las respuestas anteriores.
Esto se reduce a cómo funcionan los límites de los tokens.
Cada chat comparte un único presupuesto simbólico. Esto incluye el mensaje del sistema, tus indicaciones, el historial de conversaciones y la respuesta de la modelo. A medida que el chat crece, ya se utilizan más tokens antes de que ChatGPT comience a generar una respuesta.
La longitud del contexto y la longitud de la respuesta también son diferentes. Un modelo puede aceptar una entrada grande, pero aun así detenerse antes de tiempo al generar la salida. En la mayoría de las interfaces de ChatGPT, la longitud de la respuesta está limitada por debajo de la ventana de contexto completa.
Es por eso que los chats largos a veces pierden detalles anteriores o se interrumpen a mitad de la respuesta. No es un error. Es el modelo que está llegando a su límite.
Algunos usuarios también exploran herramientas basadas en el navegador, como Chat GPT Atlas para organizar largas charlas. Estas herramientas no aumentan los límites de los tokens, pero ayudan a gestionar mejor las conversaciones.
¿Cuáles son las diferencias entre ChatGPT-3.5 y ChatGPT-4?
Sobre el papel, tanto el GPT-3.5 como el GPT-4 generan texto. En la práctica, se comportan de forma muy diferente una vez que se empieza a trabajar con entradas más largas, tareas complejas o conversaciones continuas.
Hemos notado esta diferencia con mayor claridad al pasar de las instrucciones breves al trabajo real, como revisar las transcripciones o repetir tareas de varios pasos.
Límites de salida y ventana de contexto
GPT-3.5 Turbo admite una ventana de contexto de 16K, pero su salida máxima está limitada a 4.096 tokens. Esto significa que las solicitudes largas desplazan rápidamente el espacio disponible para una respuesta.
Chat GPT-4O, por el contrario, admite una ventana de contexto de 128 000 y puede generar respuestas de hasta 16 384 tokens. Puedes proporcionar muchos más antecedentes sin llegar inmediatamente a los límites.
GPT-4.1 lleva esto aún más lejos en los casos de uso de API, con una ventana de contexto de token de más de 1 millón y límites de producción mucho más altos. Esto cambia la forma de abordar los documentos grandes y los largos historiales de conversaciones.
Diferencias de capacidad y razonamiento
GPT-3.5 está optimizado para la generación básica de texto y código. Funciona para tareas sencillas, pero tiene problemas con:
- Instrucciones largas
- Lógica de varios pasos
- Mantener la coherencia en una conversación
GPT-4Los modelos de primera clase los manejan mejor. Los hemos encontrado:
- Siga las instrucciones más de cerca
- Pierde el contexto con menos frecuencia
- Producir respuestas más estructuradas y coherentes
No se trata solo de fichas. La arquitectura subyacente y los datos de entrenamiento son diferentes, lo que reduce las alucinaciones y mejora la precisión del razonamiento.
Modalidades y características
GPT-3.5 es de solo texto y admite un conjunto de funciones limitado.
Chat GPT-4O apoya:
- Entrada de texto e imagen
- Mayor manejo del contexto
- Mejor rendimiento en los flujos de trabajo basados en chat
GPT-4.1 añade compatibilidad con funciones avanzadas de API, como llamadas a herramientas, salidas estructuradas y procesamiento de mayor volumen, lo que la hace más adecuada para los sistemas de producción.
Costo y uso recomendado
GPT-3.5 es más económico por token y sigue apareciendo en las tareas de API sensibles a los costos. Dicho esto, OpenAI ahora recomienda modelos más nuevos para la mayoría de los casos de uso.
En flujos de trabajo reales, Modelos de clase GPT-4 son más confiables una vez que las instrucciones superan unos pocos párrafos o las tareas requieren un contexto sostenido.
La verdadera comida para llevar
La diferencia entre GPT-3.5 y GPT-4 no es solo la cantidad de tokens que admiten.
Es lo bien que:
- Administrar el contexto
- Siga las instrucciones
- Maneje entradas largas sin averiarse
Las fichas importan, pero son solo una parte de la historia.
Cómo sortear los límites de los tokens
Los límites de los tokens son menos restrictivos de lo que solían ser. Sin embargo, siguen determinando cuánto puede procesar y devolver un modelo en una sola respuesta. En la práctica, el enfoque correcto depende de la elección del modelo, la estructura rápida y la forma en que se gestione el contexto a lo largo del tiempo.
Utilice modelos con ventanas de contexto más grandes
Si tiene acceso, comience con modelos diseñados para contextos largos.
Los modelos más nuevos, como el GPT-5, el GPT-4o y el GPT-4.1, admiten ventanas de contexto mucho más amplias que las generaciones anteriores. Esto reduce la frecuencia con la que necesitas recortar las entradas o reiniciar una conversación cuando trabajas con textos largos o tareas en curso.
Dicho esto, el contexto más amplio no elimina todos los límites.
La salida sigue limitada
Incluso cuando un modelo puede aceptar entradas grandes, los tokens de salida máximos pueden ser mucho más pequeños. Esto suele aparecer cuando una respuesta finaliza antes de tiempo o parece incompleta.
Cuando eso suceda:
- Pídele a la modelo que continúe con un mensaje de seguimiento
- Solicite un resumen en lugar de una reproducción completa
- Divida la tarea en varios pasos
Esto ayuda a mantener cada respuesta dentro del límite de salida del modelo.
Divida las entradas grandes intencionalmente
La fragmentación sigue siendo útil, incluso con los modelos modernos.
Por lo general, dividimos el contenido largo por:
- Secciones
- Temas
- Intervalos de tiempo en las transcripciones
Cada fragmento se procesa por separado y, a continuación, se combina o resume. Esto reduce la presión simbólica y permite que las respuestas sean más centradas.
Usa resúmenes para preservar el contexto
En lugar de continuar con el historial completo de la conversación, resume los mensajes anteriores y reutiliza ese resumen como entrada.
Esto mantiene el contexto compacto a la vez que conserva los detalles clave. Es especialmente útil en chats prolongados y flujos de trabajo de varios pasos.
Mejores prácticas de API
Si estás trabajando con la API:
- Set max_tokens para cada llamada a la API
- Transmita las respuestas para evitar salidas individuales de gran tamaño
- Mantenga el estado manualmente en lugar de reenviar el historial completo de la conversación
Incluso con el GPT-5 y los modelos de contexto extendido, el uso cuidadoso de los tokens sigue siendo importante.
Simplifique las preguntas complejas
Las explicaciones largas y las transcripciones completas utilizan los tokens rápidamente. Nos hemos topado con esto a menudo con notas de la reunión.
En lugar de pegarlo todo, concéntrate en lo esencial. Por ejemplo:
«Resuma las principales decisiones y acciones de esta conversación».
Esto reduce el tamaño de entrada y genera respuestas más claras.
Cuando las soluciones alternativas no son suficientes
Incluso con modelos como el GPT-5 o el GPT-4.1, resumir y fragmentar aún requiere esfuerzo. En algún momento, el problema deja de ser el límite simbólico y se convierte en una sobrecarga del flujo de trabajo.
Ahí es donde las herramientas creadas para organizar transcripciones y salidas largas comienzan a ser importantes.
Cómo maneja Tactiq las transcripciones largas más allá de los límites de los tokens de ChatGPT
Las ventanas contextuales grandes ayudan. Sin embargo, cuando el trabajo implica largas transcripciones y reuniones recurrentes, el desafío radica menos en las fichas que en la estructura.
Tactiq es una herramienta de inteligencia artificial para la transcripción y toma de notas de reuniones diseñada para reuniones en línea. Captura las transcripciones en tiempo real y las convierte en resúmenes, elementos de acción y notas con capacidad de búsqueda.
Tactiq funciona con Zoom, Microsoft Teams y Google Meet. Puedes empezar de forma gratuita, sin necesidad de una suscripción de pago.
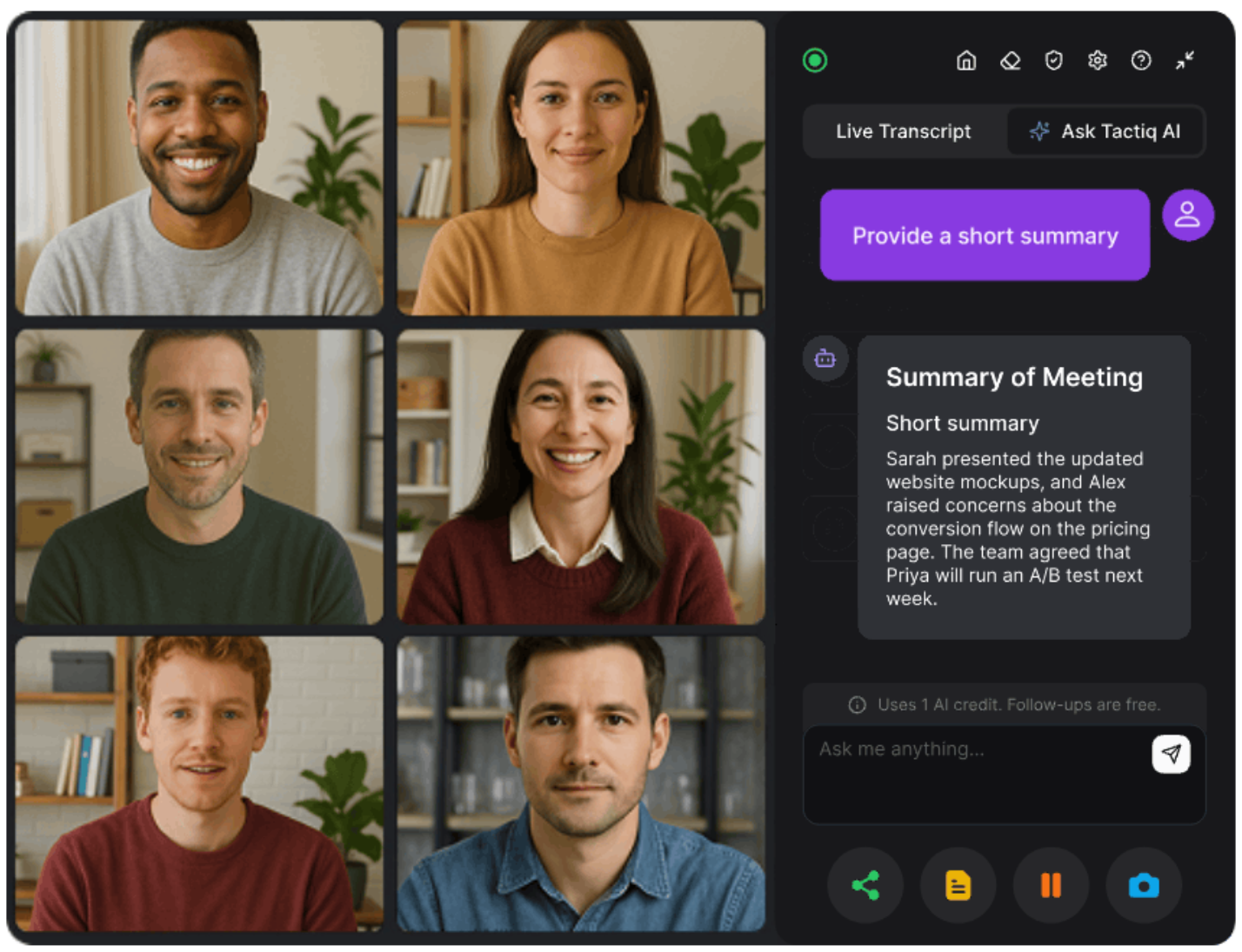
Ventajas clave:
- Captura las transcripciones completas de las reuniones sin necesidad de copiarlas manualmente
- Estructura las notas en resúmenes y elementos de acción
- Permite buscar conversaciones después de la reunión
- Reduce la escritura rápida y la gestión del contexto
- Funciona bien para reuniones recurrentes y discusiones largas
Incluso con modelos de contexto extendido como GPT-5 o GPT-4.1, organizar conversaciones largas aún requiere esfuerzo. Tactiq se centra en convertir el contenido de las reuniones en resultados utilizables, no solo en contener más contexto.
Instala la extensión gratuita de Tactiq para Chrome para capturar, organizar y reutilizar los datos de las reuniones sin preocuparse por los límites de los tokens.
Finalizando
Los límites de los tokens siguen siendo importantes, incluso cuando los modelos admiten ventanas de contexto más grandes. Determinan la cantidad de información que puede procesar un modelo, la duración de una respuesta y la confiabilidad con la que se transmite el contexto en una conversación.
Los modelos más nuevos, como el GPT-4o, el GPT-4.1 y el GPT-5, reducen la fricción, pero no la eliminan. Las transcripciones largas, las reuniones repetidas y el trabajo de seguimiento aún requieren estructura, no solo más fichas.
ChatGPT funciona bien para generar respuestas. Para los flujos de trabajo que requieren muchas reuniones, las herramientas como Tactiq se centran en convertir las conversaciones en resúmenes, elementos de acción y notas en las que se pueden buscar y que siguen siendo útiles una vez que finaliza el chat.
Si trabajas habitualmente con contenido de reuniones de formato largo, la combinación de modelos de gran contexto con una herramienta diseñada específicamente puede ahorrar tiempo y reducir la sobrecarga manual.
{{rt_cta_ai-conveniencia}}
Preguntas frecuentes sobre el límite de tokens para ChatGPT 3.5 y ChatGPT 4
¿Cuál es el límite de tokens para ChatGPT-4?
No hay un límite único. Los límites de los tokens de ChatGPT-4 dependen del modelo y la plataforma. ChatGPT-4O admite una ventana de contexto de 128 000 tokens con hasta 16 384 tokens de salida, mientras que los modelos de API como el GPT-4.1 admiten límites mucho mayores.
¿Cuál es la diferencia entre GPT-3.5 y GPT-4o?
El GPT-3.5 maneja indicaciones breves y tareas básicas, pero tiene un contexto más pequeño y una menor capacidad de razonamiento. El GPT-4o admite un contexto mucho más amplio, un razonamiento más sólido y la entrada de imágenes, lo que lo hace ideal para conversaciones largas y tareas complejas.
¿Cuál es el límite de fichas para GPT-4o?
GPT-4o admite una ventana de contexto de 128 000 tokens y hasta 16 384 tokens de salida. Los tokens de entrada y salida comparten el mismo presupuesto, y es posible que se apliquen límites de respuesta en la interfaz de usuario de ChatGPT.
¿El GPT-4 todavía tiene un límite?
Sí. Todos los modelos GPT tienen límites. Incluso con ventanas de contexto grandes, los modelos siguen limitando el tamaño máximo de salida y el total de tokens por solicitud según el modelo y el método de acceso.
¿Cuántos tokens puede manejar ChatGPT-3.5?
GPT-3.5 Turbo admite un total de 16.385 tokens por solicitud de API, con una salida máxima de 4.096 tokens. Se considera un modelo heredado y se utiliza principalmente para tareas ligeras o sensibles a los costos.
Artículos relacionados








Get live transcriptions without an AI bot joining the meeting.
Prueba Tactiq para tu próxima reunión.
¿Quiere disfrutar de la comodidad de los resúmenes de IA?
Prueba Tactiq para tu próxima reunión.
¿Quiere disfrutar de la comodidad de los resúmenes de IA?
Prueba Tactiq para tu próxima reunión.