Qual é o limite de token para o ChatGPT 3.5 e o ChatGPT 4?
September 9, 2024
September 9, 2024
January 10, 2026
January 10, 2026

Bate-papo GPT pode lidar com grandes quantidades de texto. Mas cada bate-papo, solicitação e resposta ainda atinge um limite de tokens.
Esses limites afetam a quantidade de contexto que um modelo pode processar, a duração de uma resposta e o quão bem o ChatGPT se lembra de mensagens anteriores. As regras também mudaram muito desde o GPT-3.5 e o início do GPT-4.
Neste guia, você aprenderá:
- O que é um token ChatGPT e como o uso do token é medido
- Como os limites de token diferem entre os modelos e plataformas do ChatGPT
- Os limites atuais de token para GPT-3.5, GPT-4, GPT-4o e GPT-4.1
- Maneiras práticas de trabalhar dentro dos limites do modelo
- Quando ferramentas como o Tactiq melhoram fluxos de trabalho longos além do tamanho do token
O que é um token ChatGPT?
Um token ChatGPT é uma unidade de texto que um modelo de linguagem processa.
Um token pode ser:
- Uma única palavra
- Parte de uma palavra
- Pontuação ou símbolos
- Espaços ou caracteres que não estejam em inglês
Em média, um token equivale a cerca de 0,75 palavras em inglês. Essa medição é consistente em todos os modelos.
A contagem de palavras e a contagem de fichas estão relacionadas, mas não são iguais. Palavras mais longas, códigos e textos que não estejam em inglês geralmente usam mais símbolos do que o esperado.
Os tokens são usados em toda a interação:
- Mensagem do sistema
- Prompt do sistema
- Entrada do usuário
- Resposta do modelo
Quando o limite de tokens do modelo é atingido, o modelo deve reduzir ou interromper sua saída.
Você pode acessar Tokenizador do OpenAI para visualizar como seu modelo de linguagem de IA tokeniza um texto e mostra sua contagem total de tokens. Aqui está um exemplo de texto que inseri no Tokenizer:
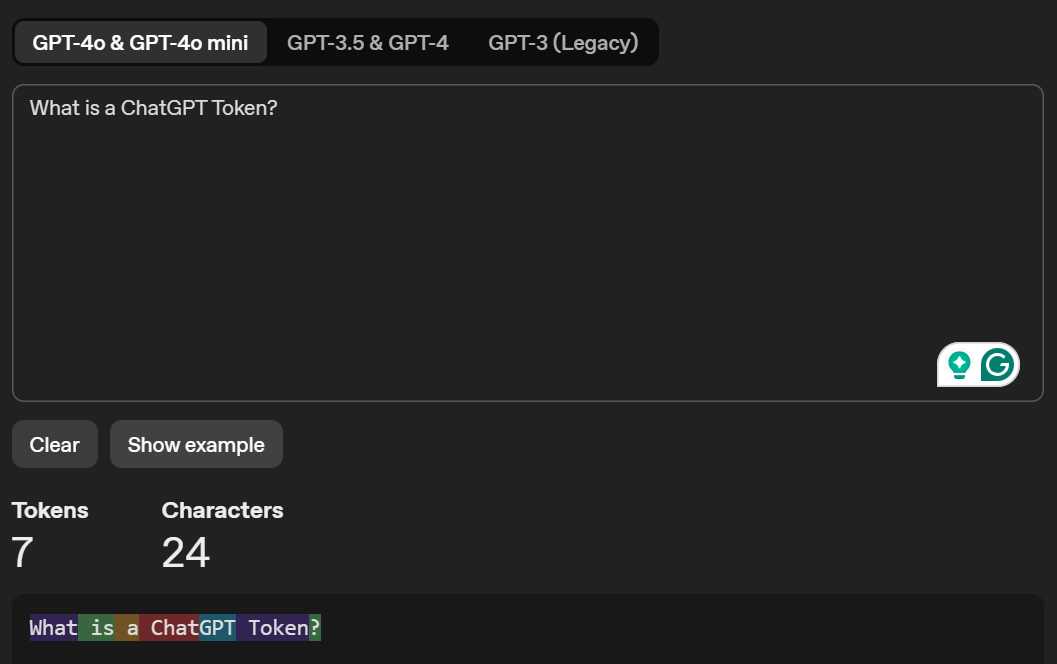
Você também pode aprender mais sobre limites de tokens ChatGPT gratuitos versus pagos.
Dica profissional: As transcrições das reuniões geralmente excedem 20.000 tokens, forçando você a fragmentar o texto ou perder o contexto no ChatGPT. Tática captura e resume reuniões do Zoom, do Google Meet e do Microsoft Teams automaticamente. Sem limites de token ou necessidade de copiar e colar.
Qual é o limite de token do ChatGPT-3.5?
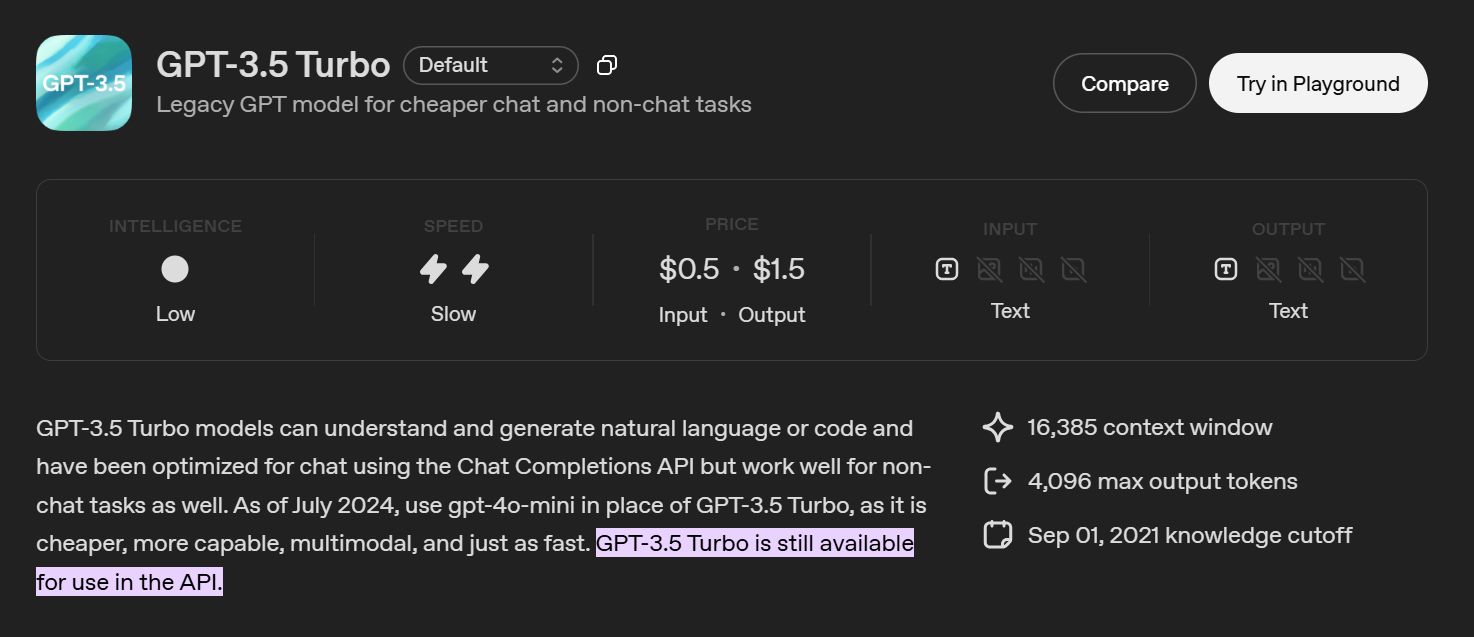
GPT-3,5 agora é considerado um modelo antigo do ChatGPT. A maioria dos usuários não o vê mais na interface do ChatGPT. Ele está disponível principalmente por meio da API ChatGPT.
O modelo gpt-3.5-turbo padrão suporta:
- Total de 16.385 tokens por solicitação de API
- Os tokens são compartilhados entre entradas, mensagens do sistema, histórico de conversas e saídas
- A resposta do modelo deve caber no orçamento restante do token
Um prompt longo ou uma entrada grande reduz o tamanho máximo da resposta.
Onde o GPT-3.5 ainda é usado
- Ferramentas e scripts baseados em API
- Tarefas econômicas
- Solicitações curtas e fluxos de bate-papo simples
O GPT-3.5 não foi projetado para transcrições longas, documentos grandes ou raciocínios complexos. Os modelos mais novos lidam com um tamanho de contexto maior e uma saída estruturada de forma mais confiável.
Qual é o limite de token do ChatGPT-4?
O ChatGPT-4 não tem um limite fixo de tokens. Os limites variam de acordo com modelo e plataforma.
GPT-4 antigo
Praticamente obsoleto.
- Tamanho do contexto: ~ 8.192 fichas
Bate-papo GPT-4O (Bate-papo GPT)
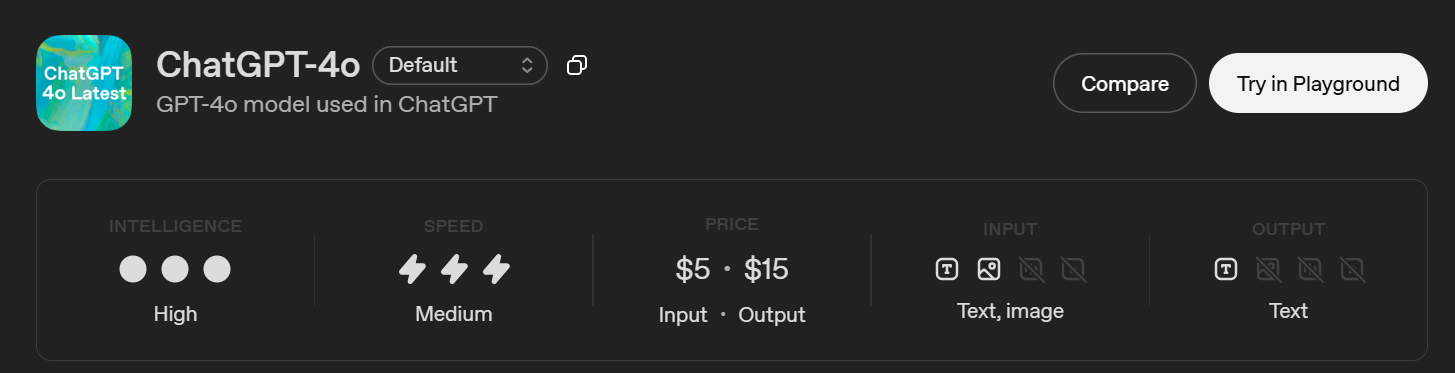
Este é o modelo GPT-4 usado no ChatGPT.
- Janela de contexto: 128.000 tokens
- Saída máxima: 16.384 fichas
- Limite de conhecimento: 1 de outubro de 2023
O ChatGPT ainda aplica limites de resposta, então o modelo pode aceitar uma entrada grande, mas retornar uma resposta mais curta.
GPT-4.1 (somente API)
Criado para cargas de trabalho estruturadas e de formato longo.
- Janela de contexto: 1.047.576 tokens
- Saída máxima: 32.768 tokens
- Limite de conhecimento: 1 de junho de 2024
Ponto chave
Não há limite único de tokens do ChatGPT-4. Os limites dependem de:
- O modelo ChatGPT
- Interface de usuário do ChatGPT versus API OpenAI
- Comprimento do contexto versus limite de saída
Como funcionam os limites de token do ChatGPT?
Se você já usou Bate-papo GPT para sessões mais longas, você provavelmente notou que as respostas ficam mais curtas com o tempo. Vimos isso acontecer depois de colar um texto longo, continuar uma conversa ou fazer perguntas complementares sobre respostas anteriores.
Isso se resume à forma como os limites de tokens funcionam.
Cada chat compartilha um único orçamento de token. Isso inclui a mensagem do sistema, suas solicitações, o histórico da conversa e a resposta do modelo. À medida que o chat cresce, mais tokens já são usados antes mesmo do ChatGPT começar a gerar uma resposta.
A duração do contexto e a duração da resposta também são diferentes. Um modelo pode aceitar uma entrada grande, mas ainda assim parar cedo ao gerar uma saída. Na maioria das interfaces do ChatGPT, o comprimento da resposta é limitado abaixo da janela de contexto completa.
É por isso que conversas longas às vezes perdem detalhes anteriores ou são interrompidas no meio da resposta. Não é um bug. É o modelo atingindo seu limite.
Alguns usuários também exploram ferramentas baseadas em navegador, como Atlas do ChatGPT para organizar conversas longas. Essas ferramentas não aumentam os limites de tokens, mas ajudam a gerenciar melhor as conversas.
Quais são as diferenças entre o ChatGPT-3.5 e o ChatGPT-4?
No papel, o GPT-3.5 e o GPT-4 geram texto. Na prática, eles se comportam de maneira muito diferente quando você começa a trabalhar com entradas mais longas, tarefas complexas ou conversas contínuas.
Sentimos essa diferença com mais clareza ao passar de instruções curtas para o trabalho real, como revisar transcrições ou repetir tarefas de várias etapas.
Janela de contexto e limites de saída
GPT-3.5 Turbo suporta uma janela de contexto de 16K, mas sua saída máxima é limitada a 4.096 tokens. Isso significa que solicitações longas rapidamente eliminam o espaço disponível para uma resposta.
Bate-papo GPT-4O, por outro lado, suporta uma janela de contexto de 128K e pode gerar respostas de até 16.384 tokens. Você pode fornecer muito mais informações sem atingir os limites imediatamente.
GPT-4,1 aumenta ainda mais isso em casos de uso de API, com uma janela de contexto de token de mais de 1 milhão e limites de saída muito maiores. Isso muda a forma como você aborda documentos grandes e longos históricos de conversas.
Diferenças de capacidade e raciocínio
GPT-3,5 é otimizado para geração básica de texto e código. Funciona para tarefas simples, mas tem dificuldades com:
- Instruções longas
- Lógica de várias etapas
- Manter a consistência em uma conversa
GPT-4modelos de classe A lidam melhor com isso. Descobrimos que eles:
- Siga as instruções mais de perto
- Perca o contexto com menos frequência
- Produza respostas mais estruturadas e coerentes
Não se trata apenas de tokens. A arquitetura subjacente e os dados de treinamento são diferentes, o que reduz as alucinações e melhora a precisão do raciocínio.
Modalidades e características
GPT-3,5 é somente texto e oferece suporte a um conjunto limitado de recursos.
Bate-papo GPT-4O suporta:
- Entrada de texto e imagem
- Maior tratamento de contexto
- Melhor desempenho em fluxos de trabalho baseados em bate-papo
GPT-4,1 adiciona suporte para recursos avançados de API, como chamada de ferramentas, saídas estruturadas e processamento de maior volume, o que o torna mais adequado para sistemas de produção.
Custo e uso recomendado
GPT-3,5 é mais barato por token e ainda aparece em tarefas de API sensíveis ao custo. Dito isso, a OpenAI agora recomenda modelos mais novos para a maioria dos casos de uso.
Em fluxos de trabalho reais, Modelos da classe GPT-4 são mais confiáveis quando as solicitações ultrapassam alguns parágrafos ou as tarefas exigem um contexto contínuo.
A verdadeira lição
A diferença entre o GPT-3.5 e o GPT-4 não é apenas quantos tokens eles suportam.
É o quão bem eles:
- Gerencie o contexto
- Siga as instruções
- Lide com entradas longas sem quebrar
Os tokens são importantes, mas são apenas parte da história.
Como contornar os limites de tokens
Os limites de token são menos restritivos do que costumavam ser. Mas eles ainda determinam o quanto um modelo pode processar e retornar em uma única resposta. Na prática, a abordagem correta depende da escolha do modelo, da estrutura rápida e de como você gerencia o contexto ao longo do tempo.
Use modelos com janelas de contexto maiores
Se você tiver acesso, comece com modelos projetados para um contexto longo.
Modelos mais novos, como GPT-5, GPT-4o e GPT-4.1, suportam janelas de contexto muito maiores do que as gerações anteriores. Isso reduz a frequência com que você precisa reduzir a entrada ou reiniciar uma conversa ao trabalhar com textos longos ou tarefas em andamento.
Dito isso, o contexto maior não remove todos os limites.
A saída ainda está limitada
Mesmo quando um modelo pode aceitar entradas grandes, os tokens de saída máximos podem ser muito menores. Isso geralmente aparece quando uma resposta termina cedo ou parece incompleta.
Quando isso acontece:
- Peça à modelo que continue em uma mensagem de acompanhamento
- Solicite um resumo em vez de uma reprodução completa
- Divida a tarefa em várias etapas
Isso ajuda a manter cada resposta dentro do limite de saída do modelo.
Divida entradas grandes intencionalmente
A fragmentação ainda é útil, mesmo com modelos modernos.
Normalmente, dividimos o conteúdo longo por:
- Seções
- Tópicos
- Intervalos de tempo nas transcrições
Cada bloco é processado separadamente e, em seguida, combinado ou resumido. Isso reduz a pressão do token e mantém as respostas mais focadas.
Use resumos para preservar o contexto
Em vez de levar o histórico completo da conversa adiante, resuma as mensagens anteriores e reutilize esse resumo como entrada.
Isso mantém o contexto compacto e, ao mesmo tempo, retém os principais detalhes. É especialmente útil em bate-papos longos e fluxos de trabalho com várias etapas.
Práticas recomendadas de API
Se você estiver trabalhando por meio da API:
- Conjunto max_tokens para cada chamada de API
- Transmita respostas para evitar grandes saídas únicas
- Mantenha o estado manualmente em vez de reenviar o histórico completo da conversa
Mesmo com o GPT-5 e os modelos de contexto estendidos, o uso cuidadoso do token ainda é importante.
Simplifique perguntas complexas
Explicações longas e transcrições completas usam tokens rapidamente. Já nos deparamos com isso frequentemente com notas de reunião.
Em vez de colar tudo, concentre-se no essencial. Por exemplo:
“Resuma as principais decisões e itens de ação desta conversa.”
Isso reduz o tamanho da entrada e leva a respostas mais claras.
Quando as soluções alternativas falham
Mesmo com modelos como GPT-5 ou GPT-4.1, resumir e agrupar ainda exige esforço. Em algum momento, o problema deixa de ser um limite de token e se torna uma sobrecarga de fluxo de trabalho.
É aí que as ferramentas criadas para organizar transcrições e saídas longas começam a importar.
Como a Tactiq lida com transcrições longas além dos limites do token ChatGPT
Janelas de contexto grandes ajudam. Mas quando o trabalho envolve longas transcrições e reuniões recorrentes, o desafio é menos sobre tokens e mais sobre estrutura.
Tática é uma ferramenta de IA para transcrição de reuniões e anotações projetada para reuniões on-line. Ele captura transcrições ao vivo e as transforma em resumos, itens de ação e notas pesquisáveis.
O Tactiq funciona com Zoom, Microsoft Teams e Google Meet. Você pode começar gratuitamente, sem a necessidade de assinatura paga.
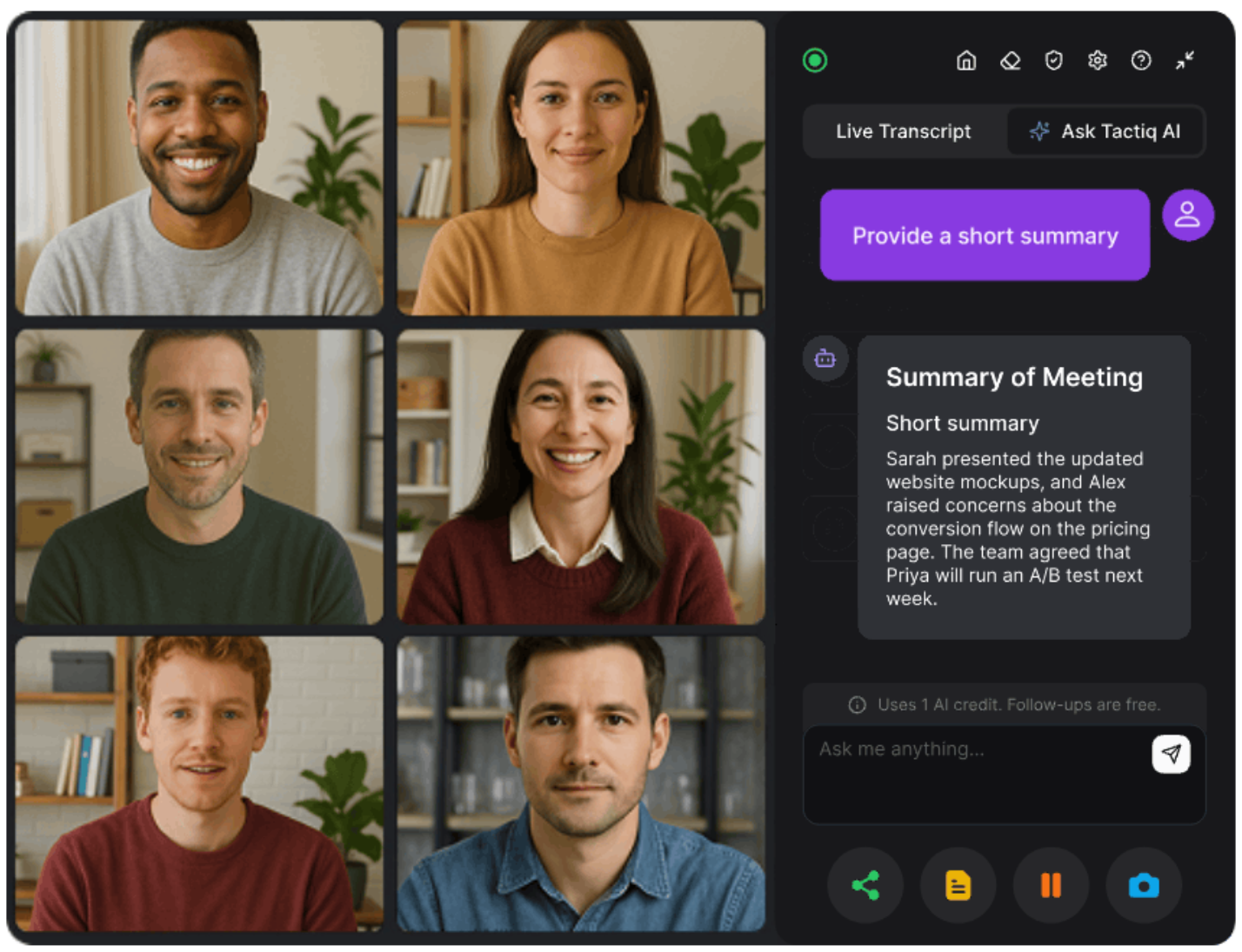
Principais benefícios:
- Captura transcrições completas da reunião sem cópia manual
- Estrutura notas em resumos e itens de ação
- Mantém as conversas pesquisáveis após a reunião
- Reduz a escrita rápida e o gerenciamento de contexto
- Funciona bem para reuniões recorrentes e longas discussões
Mesmo com modelos de contexto estendidos, como o GPT-5 ou o GPT-4.1, organizar conversas longas ainda exige esforço. A Tactiq se concentra em transformar o conteúdo da reunião em saídas utilizáveis, não apenas em manter mais contexto.
Instale a extensão gratuita do Tactiq Chrome para capturar, organizar e reutilizar insights de reuniões sem se preocupar com limites de tokens.
Encerrando
Os limites de token ainda são importantes, mesmo que os modelos suportem janelas de contexto maiores. Eles definem a quantidade de entrada que um modelo pode processar, a duração de uma resposta e a confiabilidade com que o contexto é transmitido por uma conversa.
Modelos mais novos, como GPT-4o, GPT-4.1 e GPT-5, reduzem o atrito, mas não o removem. Transcrições longas, reuniões repetidas e trabalhos de acompanhamento ainda exigem estrutura, não apenas mais fichas.
O ChatGPT funciona bem para gerar respostas. Para fluxos de trabalho pesados de reuniões, ferramentas como o Tactiq se concentram em transformar conversas em resumos, itens de ação e notas pesquisáveis que permanecem úteis após o término do bate-papo.
Se você trabalha regularmente com conteúdo de reuniões de formato longo, combinar modelos de grande contexto com uma ferramenta específica pode economizar tempo e reduzir a sobrecarga manual.
{{rt_cta_ai-conveniência}}
Perguntas frequentes sobre o limite de tokens para o ChatGPT 3.5 e o ChatGPT 4
Qual é o limite de tokens para o ChatGPT-4?
Não há um limite único. Os limites do token ChatGPT-4 dependem do modelo e da plataforma. O ChatGPT-4O suporta uma janela de contexto de 128.000 tokens com até 16.384 tokens de saída, enquanto modelos de API como o GPT-4.1 suportam limites muito maiores.
Qual é a diferença entre o GPT-3.5 e o GPT-4o?
O GPT-3.5 lida com instruções curtas e tarefas básicas, mas tem um contexto menor e menor capacidade de raciocínio. O GPT-4o suporta um contexto muito maior, raciocínio mais forte e entrada de imagens, o que o torna melhor para conversas longas e tarefas complexas.
Qual é o limite de tokens para o GPT-4o?
O GPT-4o suporta uma janela de contexto de 128.000 tokens e até 16.384 tokens de saída. Os tokens de entrada e saída compartilham o mesmo orçamento, e os limites de resposta da interface do usuário do ChatGPT podem ser aplicados.
O GPT-4 ainda tem um limite?
Sim Todos os modelos GPT têm limites. Mesmo com grandes janelas de contexto, os modelos ainda limitam o tamanho máximo de saída e o total de tokens por solicitação com base no modelo e no método de acesso.
Quantos tokens o ChatGPT-3.5 pode manipular?
O GPT-3.5 Turbo suporta um total de 16.385 tokens por solicitação de API, com uma saída máxima de 4.096 tokens. É considerado um modelo legado e é usado principalmente para tarefas leves ou econômicas.
Artigos relacionados








Quer a conveniência dos resumos de IA?
Experimente o Tactiq para sua próxima reunião.
Quer a conveniência dos resumos de IA?
Experimente o Tactiq para sua próxima reunião.
Quer a conveniência dos resumos de IA?
Experimente o Tactiq para sua próxima reunião.